
2024 年 9 月,OpenAI 发布了其 o1 模型,该模型经过大规模强化学习训练,使其具有“高级推理”能力。不幸的是,他们实现这一目标的细节从未公开分享。然而,今天,DeepSeek(一家人工智能研究实验室)复制了这种推理行为,并公布了他们方法的全部技术细节。在本文中,我将讨论这一创新背后的关键思想,并描述它们在幕后是如何工作的。
OpenAI 的 o1 模型标志着训练大型语言模型 (LLM) 的新范式。它引入了所谓的 “思考”标记,这启用了一种 便笺簿,模型可以使用它来思考 问题 和用户查询。
o1 的主要见解是,随着 测试时间计算的增加,性能得到了提高。这只是一种奇特的说法,即 模型生成的 token 越多,其响应就越好。下图摘自 OpenAI 的博客,很好地体现了这一点。
在上图中,y 轴表示模型在 AIME(数学问题)上的表现,而 x 轴表示各种计算时间。左图描绘了引发 2023 年 LLM 热潮的著名神经缩放定律。换句话说, 模型 训练的时间越长 (即训练时间计算), 其性能就越好。
然而,在右侧,我们看到了一种新型的缩放定律。在这里, 模型生成的token越多 (即测试时计算), 其性能就越好。
“思考”代币
o1 的一个关键特征是其所谓的 “思考”标记。这些是 在训练后引入的特殊标记,它们界定了模型的思路链 (CoT) 推理(即思考问题)。这些特殊标记很重要,原因有二。
一是它们明确划分了模型“思考”的起点和终点,以便在启动 UI 时轻松解析。 二是它生成了模型如何“思考”问题的人类可解释的读数。
尽管 OpenAI 透露他们使用强化学习来实现这一功能,但他们并未透露具体实现细节 。 不过,今天,得益于 DeepSeek 的最新发表,我们有了一个很好的想法。
DeepSeek 的论文
2025 年 1 月,DeepSeek 发表了《DeepSeek-R1:通过强化学习激励法学硕士中的推理能力》[2] 。 虽然这篇论文引起了不小的轰动,但其核心贡献是 揭开了 o1 背后的秘密。
它引入了两个模型: DeepSeek-R1-Zero 和 DeepSeek-R1。前者专门基于强化学习(RL)进行训练,后者则是监督微调(SFT)和 RL 的混合。
尽管标题(和论文标题)是关于 DeepSeek-R1 的,但前一个模型很重要,因为第一,它为 R1 生成了训练数据;第二,它展示了 模型未曾教授的惊人的新兴推理能力。
换句话说, R1-Zero 仅通过 RL就发现了 CoT 和测试时间计算扩展! 让我们讨论一下它是如何工作的。
DeepSeek-R1-Zero(仅限 RL)
强化学习 (RL) 是一种机器学习方法,其中模型不是通过明确的示例来训练模型,而是 通过反复试验来学习 [3]。它的工作原理是将奖励信号传递给与模型参数没有明确函数关系的模型。
这与我们经常在现实世界中学习的方式类似。例如,如果我申请了一份工作但没有得到回复,我必须弄清楚我做错了什么以及如何改进。这与监督学习形成对比,在这个比喻中,监督学习就像招聘人员就我做错了什么以及如何改进给我具体的反馈。
虽然使用 RL 训练 R1-Zero 包含许多技术细节,但我想强调三个关键细节: 提示模板、 奖励信号和 GRPO (组相对策略优化)。
1)提示模板
用于训练的模板 如下所示,其中被替换为来自(可能)复杂数学、编码和逻辑问题数据集的问题。请注意通过简单提示 包含和标签。{prompt}<answer><think>
A conversation between User and Assistant. The user asks a question, and the
Assistant solves it.The assistant first thinks about the reasoning process in
the mind and then provides the user with the answer. The reasoning process and
answer are enclosed within <think> </think> and <answer> </answer> tags,
respectively, i.e., <think> reasoning process here </think>
<answer> answer here </answer>. User: {prompt}. Assistant:这里最引人注目的是极简而轻松的提示策略。这是 DeepSeek 有意为之,以 避免模型响应出现偏差 ,并 观察其在强化学习过程中的自然演变。
2)奖励信号
RL 奖励 有 两个组成部分: 准确度和格式奖励。由于训练数据集由具有明确正确答案的问题组成,因此使用简单的基于规则的策略来评估响应准确度。同样,使用基于规则的格式奖励来确保在思考标签之间生成推理标记。
作者指出,没有使用神经奖励模型(即奖励不是由神经网络计算的),因为这些模型可能容易受到 奖励黑客攻击。换句话说, LLM 学习如何 欺骗 奖励模型以最大化奖励, 同时降低下游性能。
这就像人类会想方设法利用任何激励机制来最大化个人利益,同时却抛弃激励机制的初衷。这凸显了产生良好奖励的难度(无论对人类还是计算机而言)。
3)GRPO(组相对策略优化)
最后的细节是如何将奖励转化为模型参数更新。本节技术性很强,因此有经验的读者可以跳过。
GRPO 是一种 RL 方法,它结合了一系列响应来更新模型参数。为了促进稳定的训练,作者还将裁剪和 KL 散度正则化项纳入损失函数。裁剪确保优化步骤不会太大,正则化确保模型预测不会发生太大变化。
这是完整的损失函数,其中包含一些(希望)有用的注释。

结果(突发能力)
R1-Zero 最引人注目的结果是,尽管指导很少,但它却开发出了我们可能认识的有效推理策略。
例如,它 通过强化学习进行隐式学习,通过测试时间计算来改进响应 (回想一下 o1 中的早期见解)。下图来自 R1 论文 [2],描述了这一点。
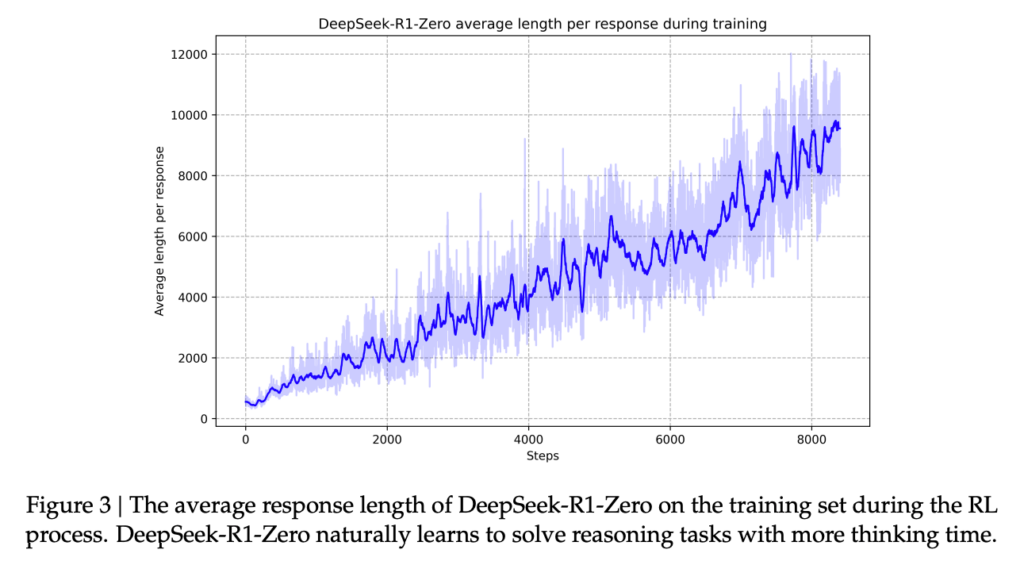
另一个值得注意的能力是,用一种不可思议的类似人类的内心独白来反思过去的回答。以下是 R1-Zero 的一个例子。请注意, 在生成最终答案之前, CoT 很长,而且还有额外的验证步骤 (我省略了一些部分,因为答案很长)。